
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MANLTIVTEFILMGFSTNKNMCILHSILFLLIYLCALMGNVLIIMITTLDHHLHTPVYFFLKNLSFLDLCLISVTAPKSIANSLIHNNSISFLGCVSQVFLLLSSASAELLLLTVMSFDRYTAICHPLHYDVIMDRSTCVQRATVSWLYGGLIAVMHTAGTFSLSYCGSNMVHQFFCDIPQLLAISCSENLIREIALILINVVLDFCCFIVIIITYVHVFSTVKKIPSTEGQSKAYSICLPHLLVVLFLSTGFIAYLKPASESPSILDAVISVFYTMLPPTFNPIIYSLRNKAIKVALGMLIKGKLTKK | |
| CCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHCCCHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSCCCCCCCCCCHHHCCCCHHHHHHHHHHHHHCCCCC | |
| 998751287754068998507999999999999999998999999997088755748899878999856266025899999871499758789999999999999999999999998650776276545760467759999999999999999999999980527999695788676878888781655249999999999999999799899999999999613865167663103609889999997205506807899898877808998520545243455322451999999999986131579 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MANLTIVTEFILMGFSTNKNMCILHSILFLLIYLCALMGNVLIIMITTLDHHLHTPVYFFLKNLSFLDLCLISVTAPKSIANSLIHNNSISFLGCVSQVFLLLSSASAELLLLTVMSFDRYTAICHPLHYDVIMDRSTCVQRATVSWLYGGLIAVMHTAGTFSLSYCGSNMVHQFFCDIPQLLAISCSENLIREIALILINVVLDFCCFIVIIITYVHVFSTVKKIPSTEGQSKAYSICLPHLLVVLFLSTGFIAYLKPASESPSILDAVISVFYTMLPPTFNPIIYSLRNKAIKVALGMLIKGKLTKK | |
| 772403000000000043340011002303311221333332002001003300000011030000100101000002000000154320001001101100010023001000100210000002002011301330000000000210231021000100002004613020000012200200013130101111221133133123203302320010001031663231000001002000013200210001031633442310000110233133003000020420130023004432368 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHCCCHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSCCCCCCCCCCHHHCCCCHHHHHHHHHHHHHCCCCC MANLTIVTEFILMGFSTNKNMCILHSILFLLIYLCALMGNVLIIMITTLDHHLHTPVYFFLKNLSFLDLCLISVTAPKSIANSLIHNNSISFLGCVSQVFLLLSSASAELLLLTVMSFDRYTAICHPLHYDVIMDRSTCVQRATVSWLYGGLIAVMHTAGTFSLSYCGSNMVHQFFCDIPQLLAISCSENLIREIALILINVVLDFCCFIVIIITYVHVFSTVKKIPSTEGQSKAYSICLPHLLVVLFLSTGFIAYLKPASESPSILDAVISVFYTMLPPTFNPIIYSLRNKAIKVALGMLIKGKLTKK | |||||||||||||||||||||||||
| 1 | 3emlA | 0.17 | 0.18 | 0.90 | 3.79 | Download | ------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ | |||||||||||||||||||
| 2 | 5tgzA | 0.20 | 0.22 | 0.88 | 2.15 | Download | -ENFMDIECFMVL----NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL------------------------PLLGWVCSDIFPHDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMELAKTLVLILVVIICWGPLLAIMVYDVFGKMNKLIKTVFAMLCLLNSTVNPIIYALRSKDLRHAFRSM-------- | |||||||||||||||||||
| 3 | 4iaqA | 0.19 | 0.20 | 0.87 | 2.23 | Download | ----------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGR----WVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL-------PPFFWRQAS--------------ECVVNTDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIIQKRERKATKTLGIILGAFIVCWLPFFIISLVMPI--HLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK---- | |||||||||||||||||||
| 4 | 4djh | 0.15 | 0.23 | 0.91 | 1.54 | Download | -----------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVRE---DVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLDRNLRRITRLVLVVVAVFVCWTPIHIFILVEALGSAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP----- | |||||||||||||||||||
| 5 | 4yay | 0.17 | 0.22 | 0.91 | 1.23 | Download | TTRNAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNV-FF------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFSWIPHQIFTFIQLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL------- | |||||||||||||||||||
| 6 | 3emlA | 0.17 | 0.18 | 0.90 | 3.98 | Download | -------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ | |||||||||||||||||||
| 7 | 4iaq | 0.18 | 0.20 | 0.60 | 1.71 | Download | --------------------WKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPF-FWRQASECVVNT-----------------DHILYT---VYSTVGAFYFPTLLLIALYGRIYVEARSR----------------------------------------------------------------------------------- | |||||||||||||||||||
| 8 | 2z73A | 0.18 | 0.22 | 0.95 | 2.56 | Download | WYNPSIVVHPHWREFDQPDAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGAYTLEGVLCNYISR------------DSTTRSNILCMFILGF---FGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCC | |||||||||||||||||||
| 9 | 3emlA | 0.17 | 0.18 | 0.90 | 5.02 | Download | ------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ | |||||||||||||||||||
| 10 | 2ydoA | 0.15 | 0.20 | 0.93 | 5.69 | Download | ---------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Generated 3D models | Estimated local accuracy of models | ||
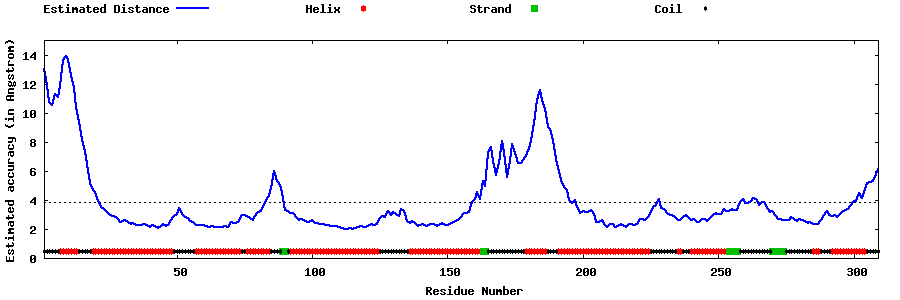 | |||
|
|
|||
 | |||
|
| |||
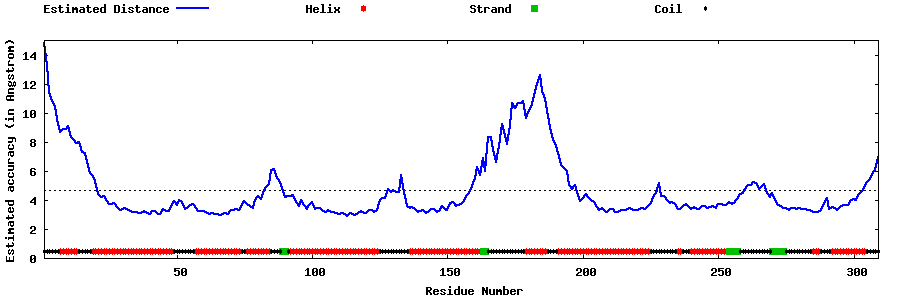 | |||
|
| |||
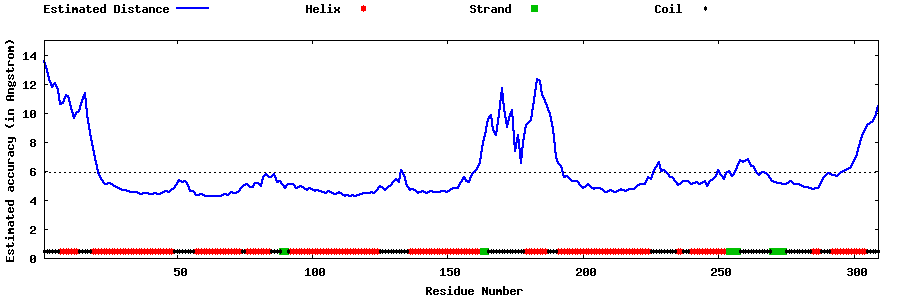 | |||
|
| |||
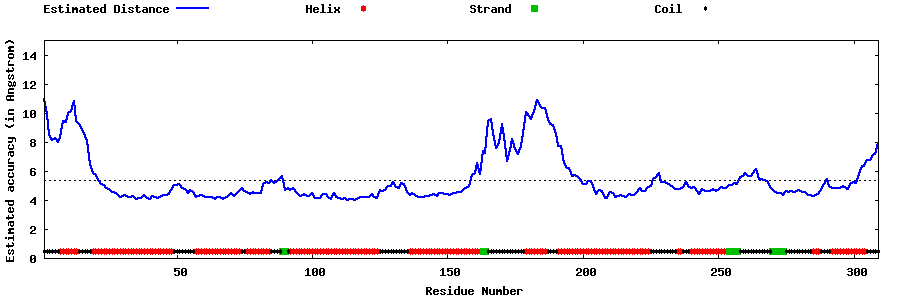 | |||
|
| |||
