| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MEFVLLGFSDIPNLHWMLFSIFLLMYLMILMCNGIIILLIKIHPALQTPMYFFLSNFSLLEICYVTIIIPRMLMDIWTQKGNISLFACATQMCFFLMLGGTECLLLTVMAYDRYVAICKPLQYPLVMNHKVCIQLIIASWTITIPVVIGETCQIFLLPFCGTNTINHFFCDIPPILKLACGNIFVNEITVHVVAVVFITVPFLLIVVSYGKIISNILKLSSARGKAKAFSTCSSHLIVVILFFGAGTITYLQPKPHQFQRMGKLISLFYTILIPTLNPIIYTLRNKDIMVALRKLLAKLLT | |
| CSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSHHCHHHCCCCHHHCCCCHHHHHHHHHHHHHHCC | |
| 9289953899852699999999999999999889998999628875675888877799998898703889898984789974868999999999999999999999999865066506555588402787999999999999999999999998462789979568860483898988524750999999999999999979999999999999982086725464154355878997999872043168178999988888289986406132123564304559999999999862369 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MEFVLLGFSDIPNLHWMLFSIFLLMYLMILMCNGIIILLIKIHPALQTPMYFFLSNFSLLEICYVTIIIPRMLMDIWTQKGNISLFACATQMCFFLMLGGTECLLLTVMAYDRYVAICKPLQYPLVMNHKVCIQLIIASWTITIPVVIGETCQIFLLPFCGTNTINHFFCDIPPILKLACGNIFVNEITVHVVAVVFITVPFLLIVVSYGKIISNILKLSSARGKAKAFSTCSSHLIVVILFFGAGTITYLQPKPHQFQRMGKLISLFYTILIPTLNPIIYTLRNKDIMVALRKLLAKLLT | |
| 5200000004315011100130233123113323200200100330000001103100110211100320300010116632010100120022003002200300020011000000210200010033000000110021013103000000010200341301000003200010002203200021223123313313310320122002000104136223201100000210010112001000010326325533000002103320330030010214201300230033327 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSHHCHHHCCCCHHHCCCCHHHHHHHHHHHHHHCC MEFVLLGFSDIPNLHWMLFSIFLLMYLMILMCNGIIILLIKIHPALQTPMYFFLSNFSLLEICYVTIIIPRMLMDIWTQKGNISLFACATQMCFFLMLGGTECLLLTVMAYDRYVAICKPLQYPLVMNHKVCIQLIIASWTITIPVVIGETCQIFLLPFCGTNTINHFFCDIPPILKLACGNIFVNEITVHVVAVVFITVPFLLIVVSYGKIISNILKLSSARGKAKAFSTCSSHLIVVILFFGAGTITYLQPKPHQFQRMGKLISLFYTILIPTLNPIIYTLRNKDIMVALRKLLAKLLT | |||||||||||||||||||||||||
| 1 | 3emlA | 0.18 | 0.20 | 0.92 | 3.68 | Download | -----------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISTG--FCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHI-INCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 2 | 5tgzA | 0.21 | 0.24 | 0.89 | 2.18 | Download | ----------NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAV--------LPLLGWNCEKL---------QSVCSDIFPHDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAMLCLLNSTVNPIIYALRSKDLRHAFRSM------ | |||||||||||||||||||
| 3 | 4iaqA | 0.19 | 0.24 | 0.89 | 2.26 | Download | ---YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL---------PPCVVNTDH--------------------ILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIIQKMAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-- | |||||||||||||||||||
| 4 | 4djh | 0.15 | 0.23 | 0.93 | 1.55 | Download | ----------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 5 | 4yay | 0.16 | 0.25 | 0.91 | 1.22 | Download | QKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLQLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL----- | |||||||||||||||||||
| 6 | 3emlA | 0.18 | 0.20 | 0.91 | 3.97 | Download | ------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 7 | 4iaq | 0.19 | 0.22 | 0.87 | 1.72 | Download | ------------PWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPF-FWRQASE----------CVVN----------TDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADARERKATKTL---GIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-- | |||||||||||||||||||
| 8 | 4ea3A | 0.20 | 0.22 | 0.83 | 3.18 | Download | -----------PGLKVTIVGLYLAVCVGGLLGNCLVMYVILRHTKMKTATNIYIFNLALADTLVLL-TLPFQGTDILLGFWPFGNALCKTVIAIDYYNMFTSTFTLTAMSVDRYVAICHPTSSKAQAVNVAIWALASVVGVPVAI--------MGSAQVEIPTPQDYWGPVFAICIFLFSF-----------------IVPVLVISVCYSLMIRRLRGVRLLSGSVAVFVGCWTPVQVFVLAQGLG-----VQPSSETAVAILRFCTALGYVNSCLNPILYAFLDENFKACFR-------- | |||||||||||||||||||
| 9 | 3emlA | 0.17 | 0.20 | 0.92 | 4.92 | Download | -----------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 10 | 2ydoA | 0.15 | 0.20 | 0.95 | 5.87 | Download | --------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWLTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| ||||||||||||||||||||||||||
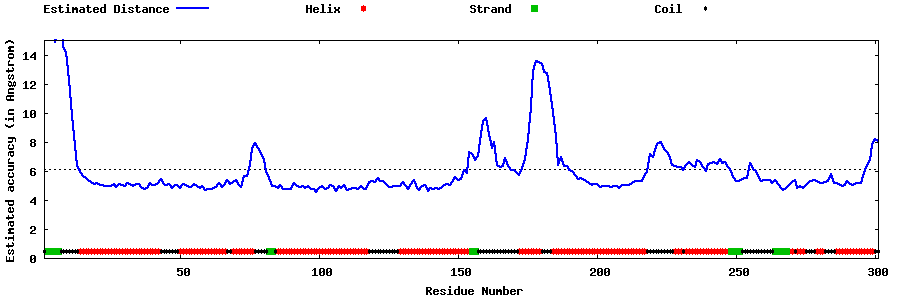
| Generated 3D models | Estimated local accuracy of models | ||
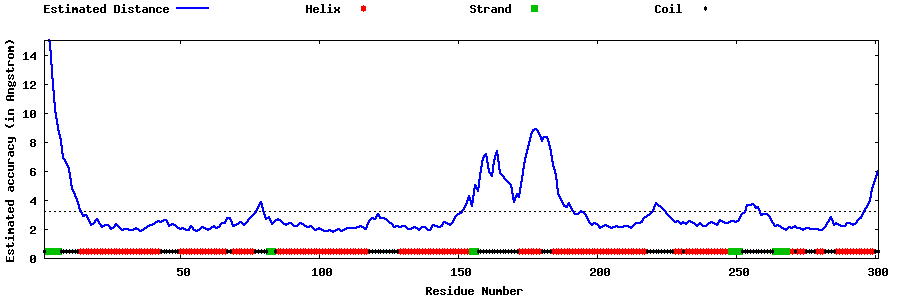 | |||
|
|
|||
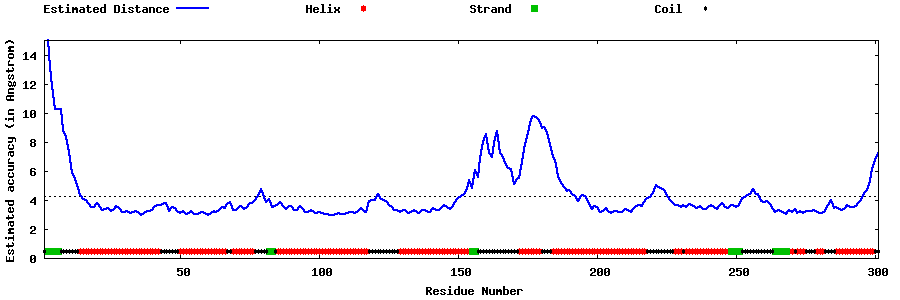 | |||
|
| |||
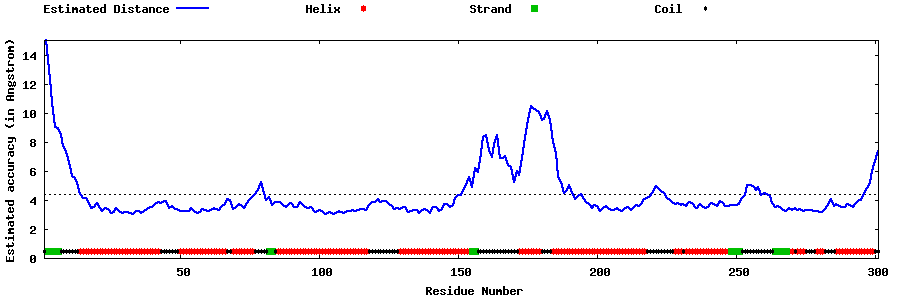 | |||
|
| |||
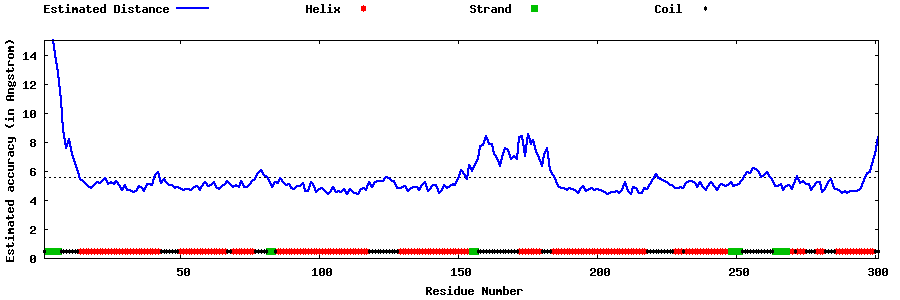 | |||
|
| |||
 | |||
|
| |||
