| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MEGINKTAKMQFFFRPFSPDPEVQMLIFVVFLMMYLTSLGGNATIAVIVQINHSLHTPMYFFLANLAVLEIFYTSSITPLALANLLSMGKTPVSITGCGTQMFFFVFLGGADCVLLVVMAYDQFIAICHPLRYRLIMSWSLCVELLVGSLVLGFLLSLPLTILIFHLPFCHNDEIYHFYCDMPAVMRLACADTRVHKTALYIISFIVLSIPLSLISISYVFIVVAILRIRSAEGRQQAYSTCSSHILVVLLQYGCTSFIYLSPSSSYSPEMGRVVSVAYTFITPILNPLIYSLRNKELKDALRKALRKF | |
| CCCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSCCCCCCCCCCCCCSSSSSHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHC | |
| 999887323677887799886279999999999999999988999898874887567488998789999888871168999999706898850689999999999999999999999997640674064444884147879999999999999999999999981458999792688604828888885248609999999999999999799999999999999932877465642442668789989998742513780789999887783899755336643014532136499999999998529 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MEGINKTAKMQFFFRPFSPDPEVQMLIFVVFLMMYLTSLGGNATIAVIVQINHSLHTPMYFFLANLAVLEIFYTSSITPLALANLLSMGKTPVSITGCGTQMFFFVFLGGADCVLLVVMAYDQFIAICHPLRYRLIMSWSLCVELLVGSLVLGFLLSLPLTILIFHLPFCHNDEIYHFYCDMPAVMRLACADTRVHKTALYIISFIVLSIPLSLISISYVFIVVAILRIRSAEGRQQAYSTCSSHILVVLLQYGCTSFIYLSPSSSYSPEMGRVVSVAYTFITPILNPLIYSLRNKELKDALRKALRKF | |
| 774523030100000000332501110013023313313332320010010033000000110200001011010023030001001662330102002201200120022001000100200000002102000200330000000100110032032001100002003423010000032000200021031102111331233233123203302320010001032463232000000000000101120000000103173364241000031033203310300001042013003300643 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSCCCCCCCCCCCCCSSSSSHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHC MEGINKTAKMQFFFRPFSPDPEVQMLIFVVFLMMYLTSLGGNATIAVIVQINHSLHTPMYFFLANLAVLEIFYTSSITPLALANLLSMGKTPVSITGCGTQMFFFVFLGGADCVLLVVMAYDQFIAICHPLRYRLIMSWSLCVELLVGSLVLGFLLSLPLTILIFHLPFCHNDEIYHFYCDMPAVMRLACADTRVHKTALYIISFIVLSIPLSLISISYVFIVVAILRIRSAEGRQQAYSTCSSHILVVLLQYGCTSFIYLSPSSSYSPEMGRVVSVAYTFITPILNPLIYSLRNKELKDALRKALRKF | |||||||||||||||||||||||||
| 1 | 3emlA | 0.21 | 0.21 | 0.88 | 3.44 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS----GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINC-FTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH | |||||||||||||||||||
| 2 | 5tgzA | 0.19 | 0.22 | 0.89 | 2.22 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKD--SRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL------------------------PLLGWNCEKLQSVDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAMLCLLNSTVNPIIYALRSKDLRHAFRSM---- | |||||||||||||||||||
| 3 | 5tgzA | 0.18 | 0.22 | 0.88 | 2.19 | Download | GRGENFMD---------IENPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDS--RNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG----WNCEKLIFPHID------------------KTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQMDIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF--- | |||||||||||||||||||
| 4 | 3uon | 0.16 | 0.20 | 0.89 | 1.55 | Download | --------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIG-YWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIV--GVRTVEDGECYIQFF---------SNAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINIFREKKVTRTILAILLAFIITWAPYNVMVLINTFCAIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM-- | |||||||||||||||||||
| 5 | 4yay | 0.16 | 0.21 | 0.92 | 1.24 | Download | LKTTRNAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWP-FGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLQLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL--- | |||||||||||||||||||
| 6 | 3emlA | 0.21 | 0.21 | 0.88 | 3.65 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGF-CAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH | |||||||||||||||||||
| 7 | 3uon | 0.17 | 0.20 | 0.62 | 1.69 | Download | -----------------------VVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTV-IGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFI--VGVRTVEDGECYIQF---------FSNAAVTFGTAIAAFYLPVIIMTVLYWHISRASKS--------------------------------------------------------------------------------- | |||||||||||||||||||
| 8 | 4buoA | 0.18 | 0.18 | 0.88 | 2.94 | Download | ----NSD-------LDVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHHPAFGDAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSGDGTHPGGLVCTPI------VDTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQRAVVIAFVVCWLPYHVRRLMFCYI-----------SDEQ------WLVYVSAAINPILYNLVSANFRQVFLSTL--- | |||||||||||||||||||
| 9 | 3emlA | 0.21 | 0.21 | 0.89 | 4.50 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISTGF---CAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH | |||||||||||||||||||
| 10 | 2ydoA | 0.18 | 0.22 | 0.92 | 5.47 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA---ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWLTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Generated 3D models | Estimated local accuracy of models | ||
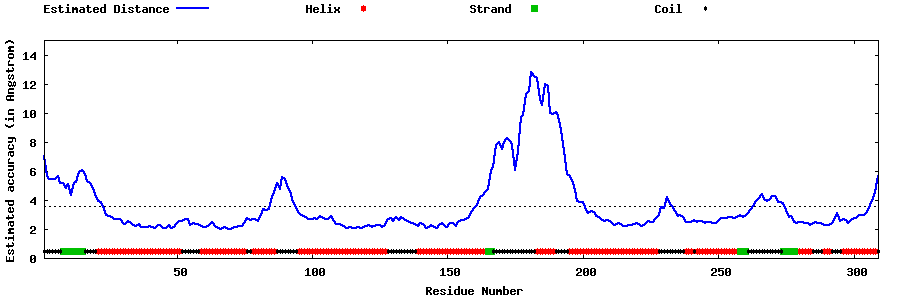 | |||
|
|
|||
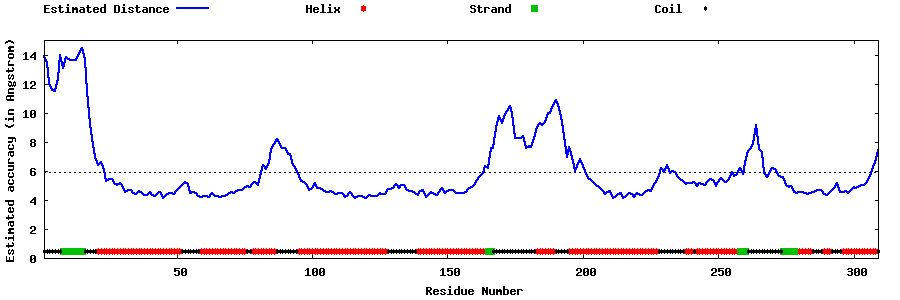 | |||
|
| |||
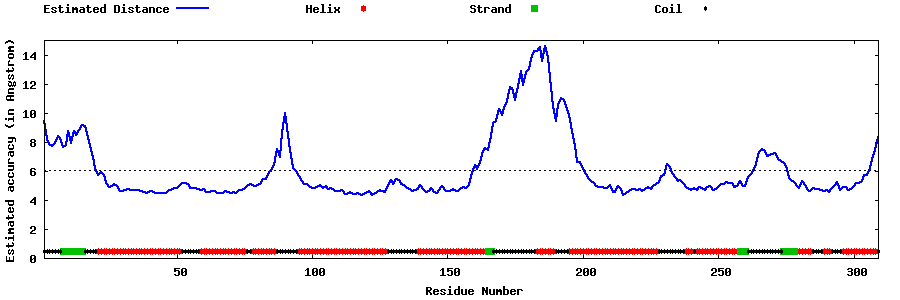 | |||
|
| |||
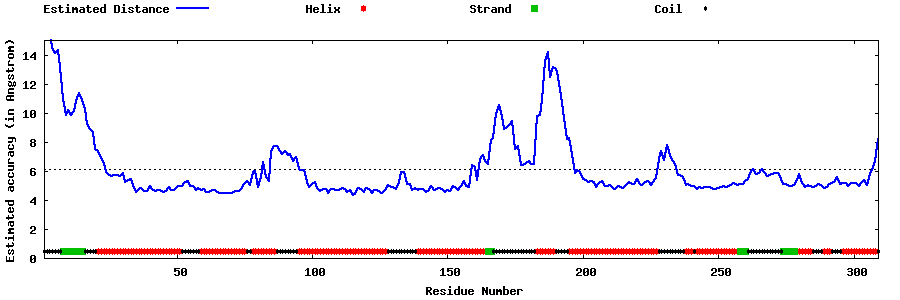 | |||
|
| |||
 | |||
|
| |||
