| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | |
| | | | | | | | | | | | | | | | |
| MMCFLLIISSILVVFAFVLGNVANGFIALVNVIDWVNTRKISSAEQILTALVVSRIGLLWVMLFLWYATVFNSALYGLEVRIVASNAWAVTNHFSMWLAASLSIFCLLKIANFSNLISLHLKKRIKSVVLVILLGPLVFLICNLAVITMDERVWTKEYEGNVTWKIKLRNAIHLSSLTVTTLANLIPFTLSLICFLLLICSLCKHLKKMRLHSKGSQDPSTKVHIKALQTVTSFLMLFAIYFLCIITSTWNLRTQQSKLVLLLCQTVAIMYPSFHSFILIMGSRKLKQTFLSVLWQMTR | |
| CCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHHCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSSSCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCSSSSSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHCCCHHHHHHHHHHHHHHCC | |
| 96589999999999999999999999999999999926989778899999999999999999997999870616312409999999999994999999999999971575378977999999865481999999999999999999971122103688884136763203589999999999999999999999999999999999997377999999983899999999999999999999999999998833556699999999999838874498841864999999999973249 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | |
| | | | | | | | | | | | | | | | |
| MMCFLLIISSILVVFAFVLGNVANGFIALVNVIDWVNTRKISSAEQILTALVVSRIGLLWVMLFLWYATVFNSALYGLEVRIVASNAWAVTNHFSMWLAASLSIFCLLKIANFSNLISLHLKKRIKSVVLVILLGPLVFLICNLAVITMDERVWTKEYEGNVTWKIKLRNAIHLSSLTVTTLANLIPFTLSLICFLLLICSLCKHLKKMRLHSKGSQDPSTKVHIKALQTVTSFLMLFAIYFLCIITSTWNLRTQQSKLVLLLCQTVAIMYPSFHSFILIMGSRKLKQTFLSVLWQMTR | |
| 73333333113313312331332022002101110045340310110000001000100321333000000012023320100010011111230000000100000000022311000001330420001102312232332212131333132543311111313133222011113333333313321331331022002202420343344431131432120000013123233323311221101232344200100012200210230000001114301300130023138 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHHCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSSSCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCSSSSSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHCCCHHHHHHHHHHHHHHCC MMCFLLIISSILVVFAFVLGNVANGFIALVNVIDWVNTRKISSAEQILTALVVSRIGLLWVMLFLWYATVFNSALYGLEVRIVASNAWAVTNHFSMWLAASLSIFCLLKIANFSNLISLHLKKRIKSVVLVILLGPLVFLICNLAVITMDERVWTKEYEGNVTWKIKLRNAIHLSSLTVTTLANLIPFTLSLICFLLLICSLCKHLKKMRLHSKGSQDPSTKVHIKALQTVTSFLMLFAIYFLCIITSTWNLRTQQSKLVLLLCQTVAIMYPSFHSFILIMGSRKLKQTFLSVLWQMTR | |||||||||||||||||||||||||
| 1 | 4djhA | 0.13 | 0.20 | 0.92 | 1.43 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIR----TKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKA----LDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPDWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSDR-----------NLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 2 | 5tjvA | 0.09 | 0.19 | 0.92 | 2.82 | Download | LNPSQQLAIAVLSLTLGTFTVLENLLVLCVILH--SRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPK----AVVAFCLMWTIAIVIAVLPLLGWNCEKLQSVCSDIF-----PHIDETYLMFWIGVTSVLLLFIVYAYMYILWKAGKRAMSFSD--------QARMDIRLAKTLVLILVVLIICWGPLLAIMVYDVFGKMKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF----- | |||||||||||||||||||
| 3 | 4djhA | 0.12 | 0.20 | 0.93 | 2.31 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRY--TKMK-TATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKAL----DFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSDR-----------NLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 4 | 4djh | 0.12 | 0.24 | 0.96 | 1.56 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIR---YTKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVC---HPVKAL-DFRTPLKAKIINICIWLLSSVGISAIVLGGKDVDVECSLQFPDDDYSWDLFMKI--CVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSGNIFTPAYREKDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 5 | 3odu | 0.14 | 0.22 | 0.97 | 1.27 | Download | NANFNKIFLPTIYSIIFLTGIVGNGLVILVMGY---QKKLRSMTDKYRLHLSVADLLFVIT-LPFWAVDAVANWYFGNFLCKAVHVIYTVNLYSSVWILAFISLDRYLAIVHATNSQRP----RKLLAEKVVYVGVWIPALLLTIPDFIFANVSEADD-RYICDRFYPNDWVVVFQFQHIMVGLILPGIVILSCYCIIISKLSHSGSNIFEMLRDAYGSKGHQKRKALKTTVILILAFFACWLPYYIGSIDSFILLVHKWISITEALAFFHCCLNPILYAFLGAKFKTSAQHALTSGRP | |||||||||||||||||||
| 6 | 4djhA | 0.13 | 0.20 | 0.93 | 1.57 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRY---TKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKA----LDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSD-----------RNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 7 | 3uon | 0.11 | 0.22 | 0.94 | 1.70 | Download | -----VVFIVLVAGSLSLVTIIGNILVMVSIKV---NRHLQTVNNYFLFSLACADLIIGVFSNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIVGVRTVE-DGECYIQFF-S--NAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINIFGADAYPPPSREKKVTRTILAILLAFIITWAPYNVMVLINTFCAP-CIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM---- | |||||||||||||||||||
| 8 | 4n6hA | 0.12 | 0.17 | 0.94 | 2.25 | Download | SSLALAIAITALYSAVCAVGLLGNVLVMFGIVRY---TKMKTATNIYIFNLALADALATSTLPFQSAKYLMETWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVK----ALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRD--GAVVCMLQFWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSV------RLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDIVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRK--P | |||||||||||||||||||
| 9 | 4djhA | 0.12 | 0.20 | 0.92 | 1.48 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIR----TKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKAL----DFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLL------------DRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 10 | 6b73A | 0.13 | 0.22 | 0.90 | 1.40 | Download | ISPAIPVIITAVYSVVFVVGLVGNSLVMFVIIR---YTKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVC---HPVKAPLKAKIINICIWLLSSSVGISAIVLGGTKVRDVIECSLQFP----DDDYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRSREKD----------RNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGTSLSSYYFCIALGYTNSSLNPILYAFLDENFKR----------- | |||||||||||||||||||
| ||||||||||||||||||||||||||
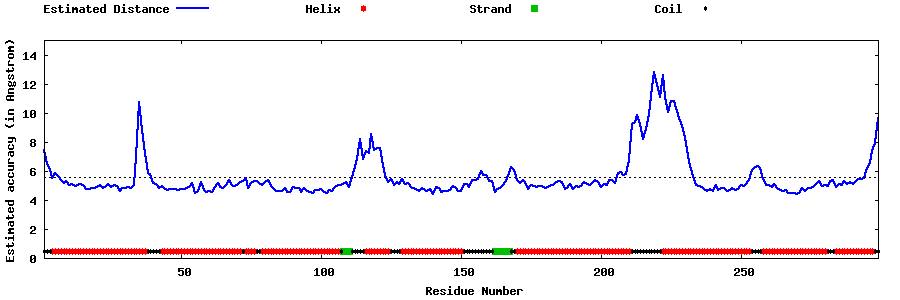
| Generated 3D models | Estimated local accuracy of models | ||
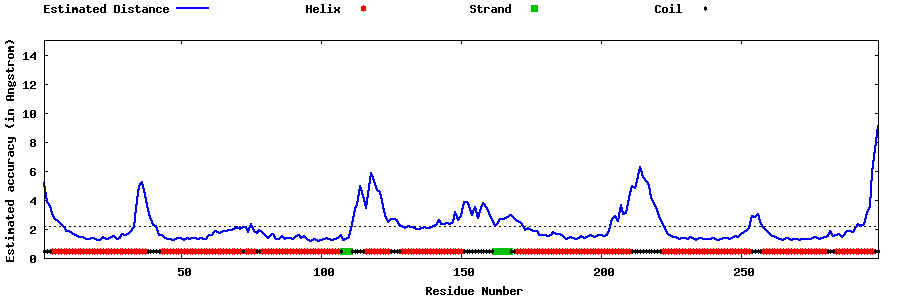 | |||
|
|
|||
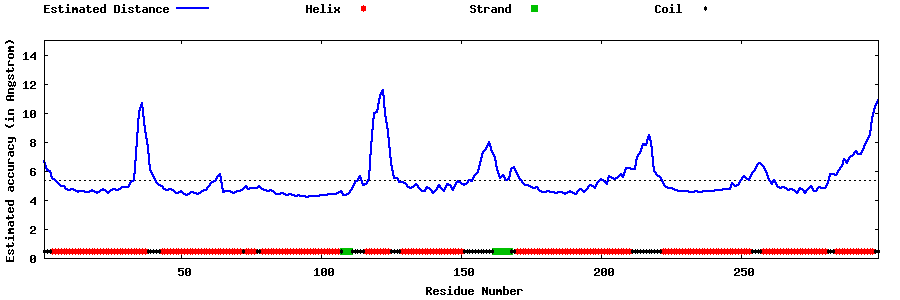 | |||
|
| |||
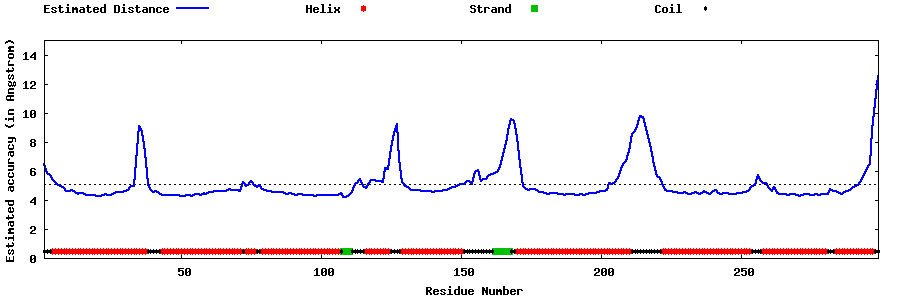 | |||
|
| |||
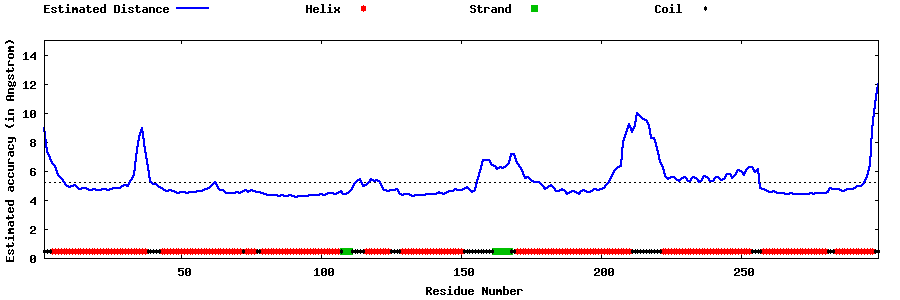 | |||
|
| |||
 | |||
|
| |||
