| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MKSWNNTIILEFLLLGISEEPELQAFLFGLFLSMYLVTVLGNLLIILATISDSHLHTPMYFFLSNLSFVDICFVSTTVPKMLVNIQTHNKVITYAGCITQMCFFLLFVGLDNFLLTVMAYDRFVAICHPLHYMVIMNPQLCGLLVLASWIMSVLNSMLQSLMVLPLPFCTHMEIPHFFCEINQVVHLACSDTFLNDIVMYFAVALLGGGPLTGILYSYSKIVSSIRAISSAQGKYKAFSTCASHLSVVSLFYGTCLGVYLSSAATHNSHTGAAASVMYTVVTPMLNPFIYSLRNKHIKGAMKTFFRGKQ | |
| CCCCCCCCCHHHHSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCSSCCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCSSSCCHHHHHHHHHHHCCHHSSSCCCCCCCCCCCCSSSSSSCCCCCCCCCCHHHCCCCHHHHHHHHHHHHCCC | |
| 999788517435210699983266899999999999999989999999971876445299998889998651450488999899835897373888899999999999999999999987506511765547841076189999999999999999999999961278998953893678799875605543898999999999999987999999999999985006676875763056265788899974804325606898788988838998500446254555424661889999999973249 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MKSWNNTIILEFLLLGISEEPELQAFLFGLFLSMYLVTVLGNLLIILATISDSHLHTPMYFFLSNLSFVDICFVSTTVPKMLVNIQTHNKVITYAGCITQMCFFLLFVGLDNFLLTVMAYDRFVAICHPLHYMVIMNPQLCGLLVLASWIMSVLNSMLQSLMVLPLPFCTHMEIPHFFCEINQVVHLACSDTFLNDIVMYFAVALLGGGPLTGILYSYSKIVSSIRAISSAQGKYKAFSTCASHLSVVSLFYGTCLGVYLSSAATHNSHTGAAASVMYTVVTPMLNPFIYSLRNKHIKGAMKTFFRGKQ | |
| 855723120010000101631521100012113012201332210000010033000000000001011011120032030010011433303020000011001100220100000001100000001020000000200000012013100200310000000001036240100001232003000111210111012213330331330033010100000020214613210000000000000011100200000012231443220000000232233001000020320230033014438 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCHHHHSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCSSCCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCSSSCCHHHHHHHHHHHCCHHSSSCCCCCCCCCCCCSSSSSSCCCCCCCCCCHHHCCCCHHHHHHHHHHHHCCC MKSWNNTIILEFLLLGISEEPELQAFLFGLFLSMYLVTVLGNLLIILATISDSHLHTPMYFFLSNLSFVDICFVSTTVPKMLVNIQTHNKVITYAGCITQMCFFLLFVGLDNFLLTVMAYDRFVAICHPLHYMVIMNPQLCGLLVLASWIMSVLNSMLQSLMVLPLPFCTHMEIPHFFCEINQVVHLACSDTFLNDIVMYFAVALLGGGPLTGILYSYSKIVSSIRAISSAQGKYKAFSTCASHLSVVSLFYGTCLGVYLSSAATHNSHTGAAASVMYTVVTPMLNPFIYSLRNKHIKGAMKTFFRGKQ | |||||||||||||||||||||||||
| 1 | 3emlA | 0.19 | 0.21 | 0.89 | 3.55 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHR | |||||||||||||||||||
| 2 | 5tgzA | 0.21 | 0.24 | 0.91 | 2.15 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFID-FHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLL-----------------GWNCEKLQSVCSDIFPHDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAMLCLLNSTVNPIIYALRSKDLRHAFRSMF---- | |||||||||||||||||||
| 3 | 4iaqA | 0.19 | 0.20 | 0.85 | 2.14 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGR----WVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL-------PPFFCVVNT----------------DHTVYSTVGAFY-------FPTLLLIALYGRIYVEARSRIIQKYLLMERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK- | |||||||||||||||||||
| 4 | 4ib4 | 0.16 | 0.21 | 0.90 | 1.54 | Download | -----------------EEQGNKLHWAALLILMVIIPTIGGNTLVILAVSLEKKLQYATNYFLMSLAVADLLVGLFVMPIALLTIMEAMWPLPLVLCPAWLFLDVLFSTASIWHLCAISVDRYIAIKKPIQANQYNSRATAFIKITVVWLISIGIAIPVPIKGI----E--TNPNNITCVLTK-------E--RFGDFMLFGSLAAFFTPLAIMIVTYFLTIHALQKKAADLEISNEQRASKVLGILFLLMWCPFFITNITLVLCDSQQMLLEIFVWIGYVSSGVNPLVYTLFNKTFRDAFGRYITCNY | |||||||||||||||||||
| 5 | 4yay | 0.19 | 0.23 | 0.92 | 1.24 | Download | KTTRN-AYIQKYLILNSSDCPYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNV-FF------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDVLIQIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL---- | |||||||||||||||||||
| 6 | 3emlA | 0.20 | 0.21 | 0.89 | 3.79 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDV-----------VPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 7 | 4iaq | 0.19 | 0.20 | 0.84 | 1.71 | Download | --------------------LPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPF-FWRQASE----------CVVNT-------D---HILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADLRERKATKTL---GIILGAF-IVCWLPFFVMPIH--L-AIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK- | |||||||||||||||||||
| 8 | 2z73A | 0.18 | 0.21 | 0.95 | 2.92 | Download | -ETWNPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGFPLMTISCFLKKIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFG------WGAYTLEGVLC---------NSRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVL | |||||||||||||||||||
| 9 | 3emlA | 0.19 | 0.21 | 0.89 | 4.87 | Download | -------------IM-------GSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHI-INCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 10 | 2ydoA | 0.18 | 0.21 | 0.92 | 5.65 | Download | -----------------S------SVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFAINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| ||||||||||||||||||||||||||
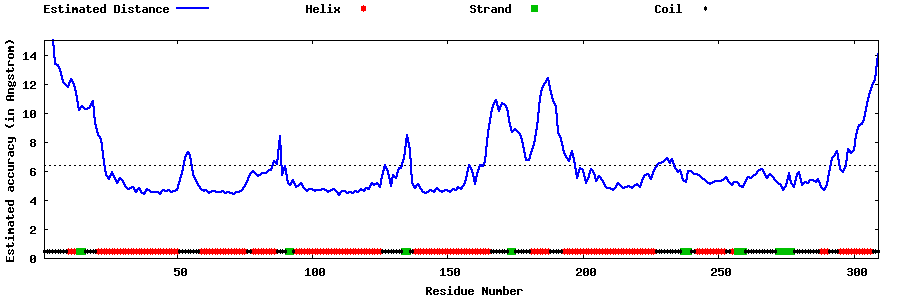
| Generated 3D models | Estimated local accuracy of models | ||
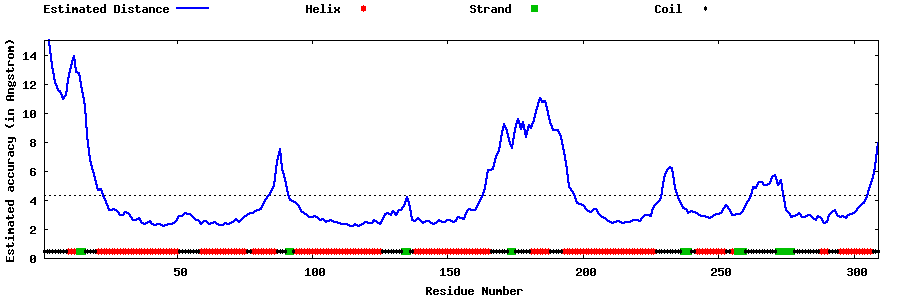 | |||
|
|
|||
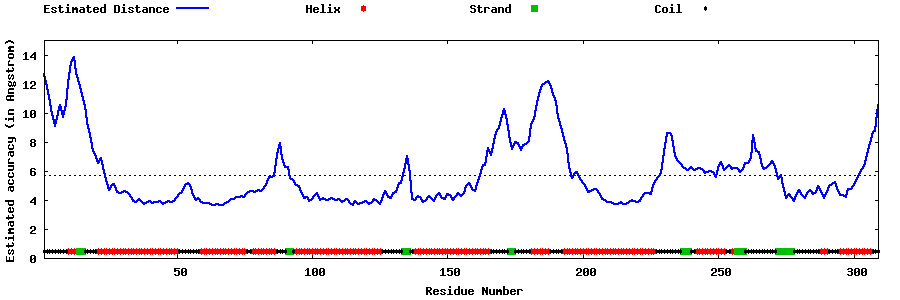 | |||
|
| |||
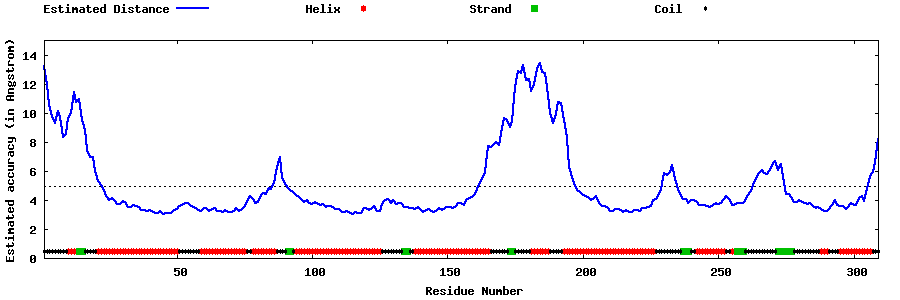 | |||
|
| |||
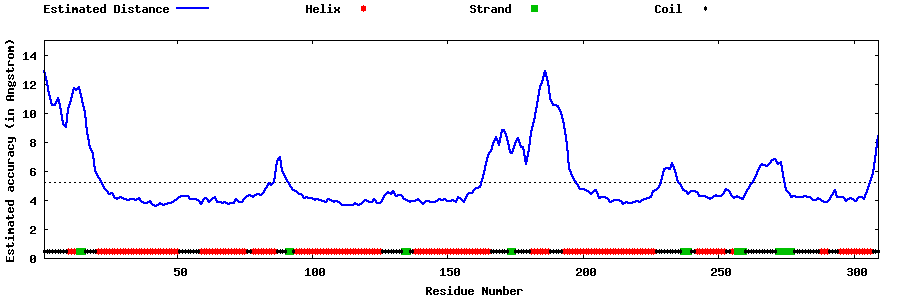 | |||
|
| |||
 | |||
|
| |||
