C-I-TASSER is a composite approach to protein structure prediction extended from I-TASSER for high-accuracy protein structure and function prediction.
C-I-TASSER uses highly accurate deep learning-based predicted contacts to guide its Replica Exchange Monte Carlo (REMC) simulations in order to generate models.
According to our benchmark, C-I-TASSER is 46% better than I-TASSER at folding distant-homology or non-homology proteins in terms of the structure model TM-scores.
C-I-TASSER is a new pipeline that integrates iterative threading assembly refinement (I-TASSER) simulations with deep learning contact-map prediction for advanced protein structure prediction. An overview of the C-I-TASSER pipeline is shown in Figure 1, which consists of five consecutive steps of residue-residue contact prediction, structural template identification, iterative fragment assembly simulations, atomic-level structure refinement and model quality estimation. Starting from the amino acid sequence, C-I-TASSER first creates a set of deep MSAs by searching the query against three whole-genome and metagenome protein sequence databases by DeepMSA. Inter-residue contact-maps are then generated by a set of six contact predictors: ResTriplet, TripletRes, ResPRE, ResPLM, and NeBcon through different deep neural-network training on the MSAs. Meanwhile, multiple template structures are collected from the PDB by LOMETS2, a meta-threading algorithm that ensembles 11 profile- and contact-based (CEthreader) threading programs. The full-length structure models are constructed by reassembling the continuous fragments excised from the LOMETS threading templates through REMC simulations under the guidance of a composite force field consisting of contact-map restraints, threading-template-derived contact and distance maps, and a set of knowledge-based energy terms highly optimized through large-scale decoy-based energy-RMSD correlations. The REMC simulations produce a variety of structural decoys, which are subsequently clustered by SPICKER to select the lowest free-energy states. Starting from the centroid of the low free-energy clusters, a second round of structure reassembly simulations are performed to refine hydrogen-bonding networks and local structure packing. The low energy conformations from the second-round of simulations are further refined at the atomic-level by fragment-guided molecular dynamics (FG-MD) simulations to generate the final models.
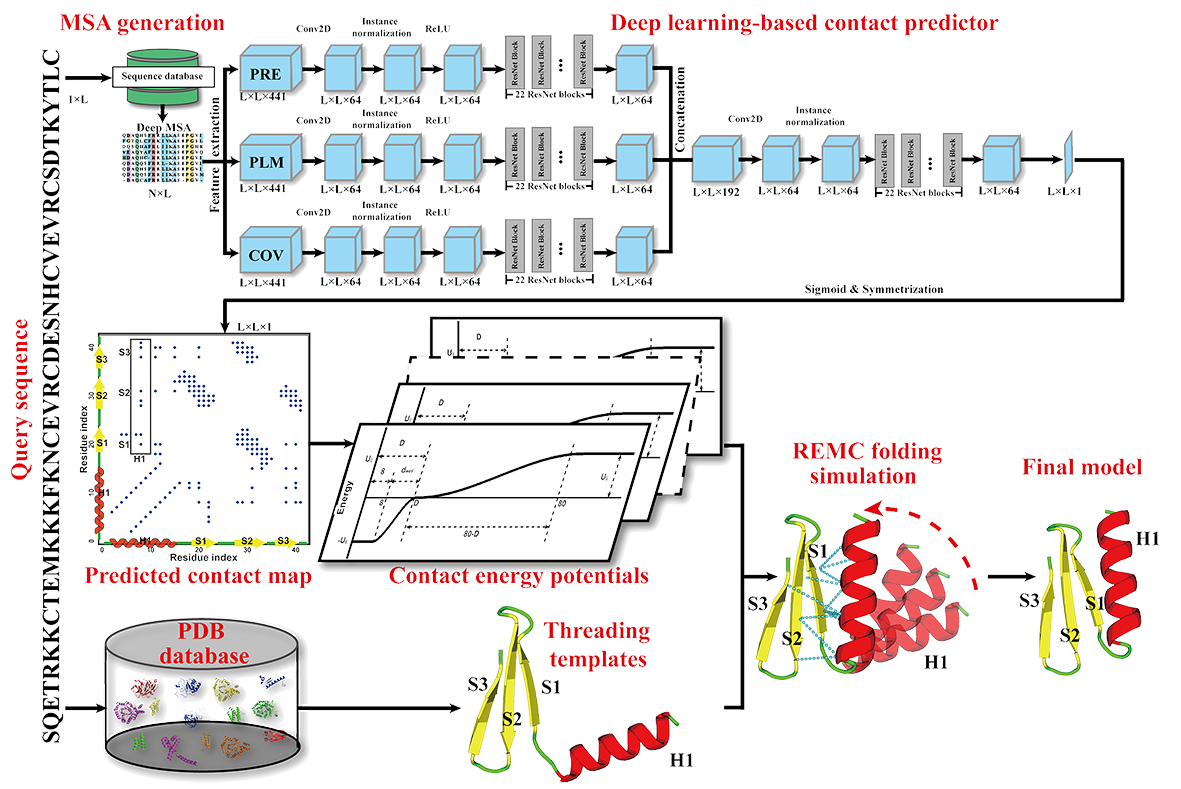 Figure 1. Pipeline of C-I-TASSER.
Figure 1. Pipeline of C-I-TASSER.
CASP (or Critical Assessment of Techniques for Protein Structure Prediction) is a community-wide experiment for testing the state-of-the-art of protein structure prediction, which has taken place every two years since 1994. The experiment is strictly blind because the structures of the test proteins are unknown to the predictors. The C-I-TASSER server (as "Zhang-Server") participated in the Server Section of CASP13 (2018), and was ranked as the No 1 automated server (Figure 2).
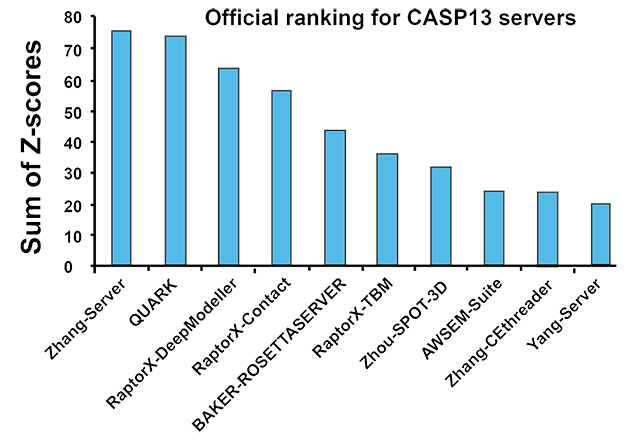 Figure 2. The results of the automated Server Section in the 13th Critical Assessment of protein Structure Prediction (CASP13) experiment. The top 10 protein structure prediction servers are shown in descending order of the Z-score of the GDT_TS score, which is a metric used to quantify the overall structure quality. The top two servers were the C-I-TASSER server (named ‘Zhang-Server’ in CASP13), and the C-QUARK server (named ‘QUARK’ in CASP13), both from our group. This figure is from the official CASP13 assessment report (Abriata et al. (2019) Proteins 87, 1100.).
Figure 2. The results of the automated Server Section in the 13th Critical Assessment of protein Structure Prediction (CASP13) experiment. The top 10 protein structure prediction servers are shown in descending order of the Z-score of the GDT_TS score, which is a metric used to quantify the overall structure quality. The top two servers were the C-I-TASSER server (named ‘Zhang-Server’ in CASP13), and the C-QUARK server (named ‘QUARK’ in CASP13), both from our group. This figure is from the official CASP13 assessment report (Abriata et al. (2019) Proteins 87, 1100.).
The user needs to paste the fasta-formatted amino acid sequence into the input box, or upload the amino acid sequence of the query protein using the "Choose file" button.
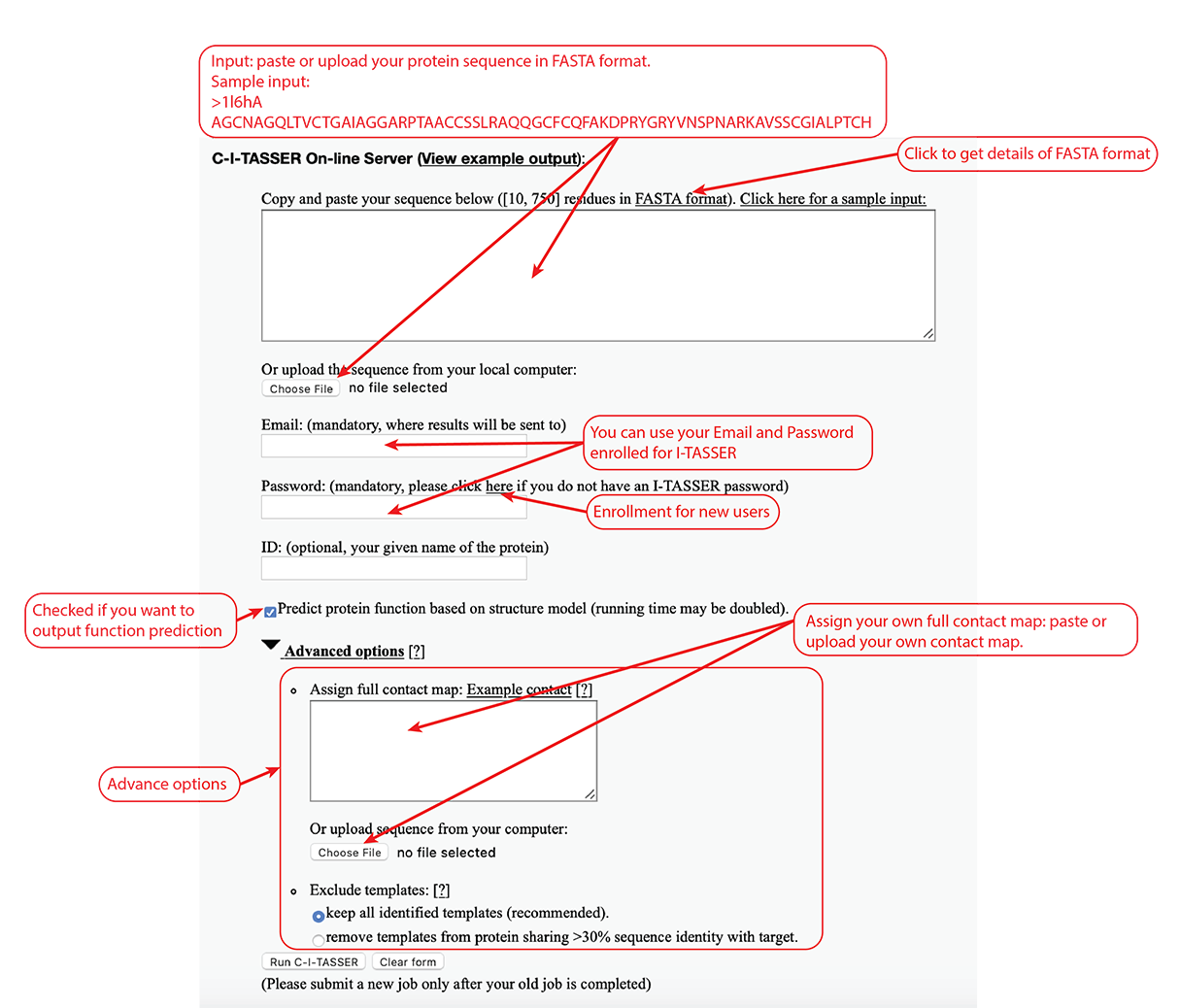 Figure 3. Input of C-I-TASSER.
Figure 3. Input of C-I-TASSER.
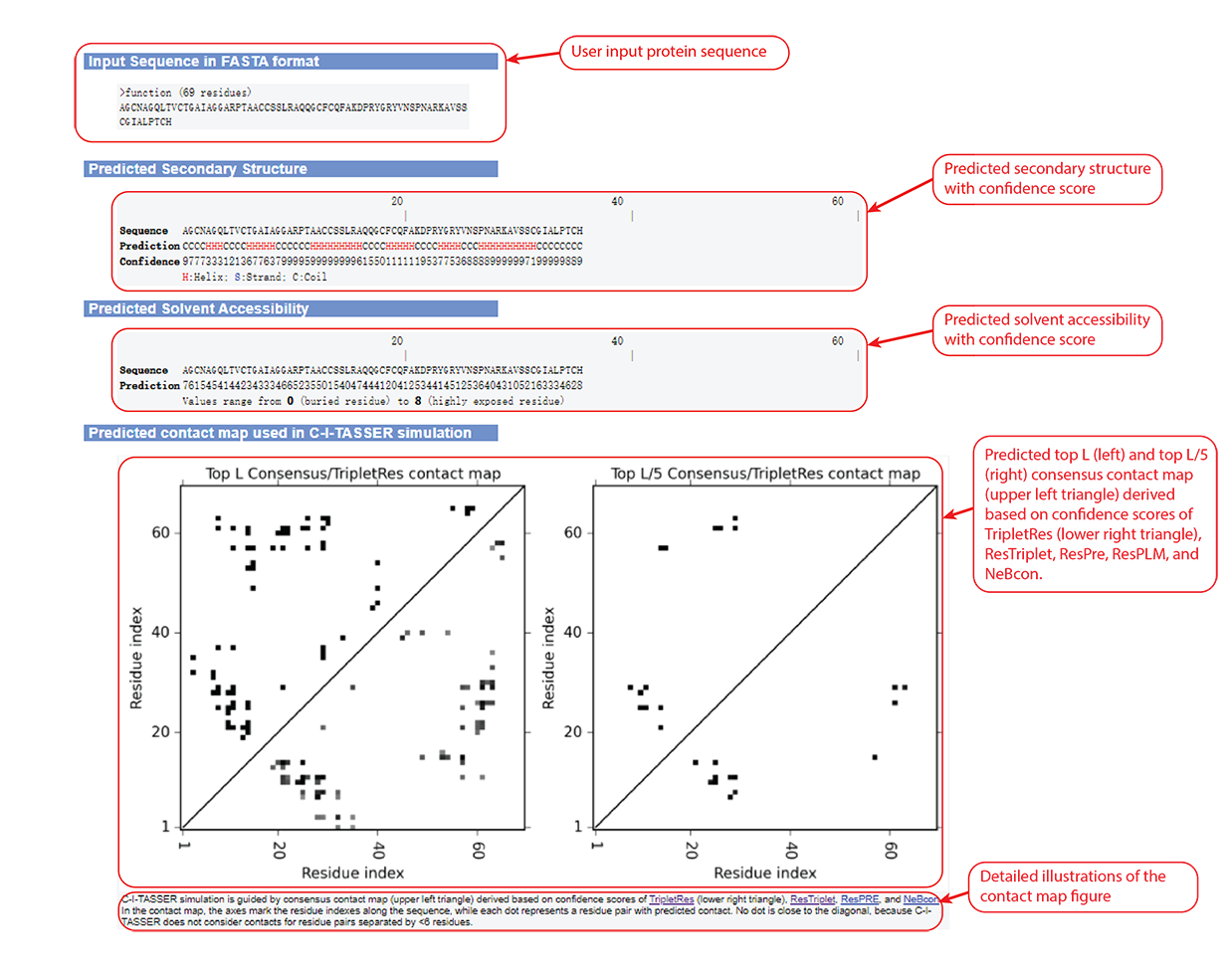 Figure 4. Secondary structure, solvent accessibility, and contact map information in the C-I-TASSER output.
Figure 4. Secondary structure, solvent accessibility, and contact map information in the C-I-TASSER output.
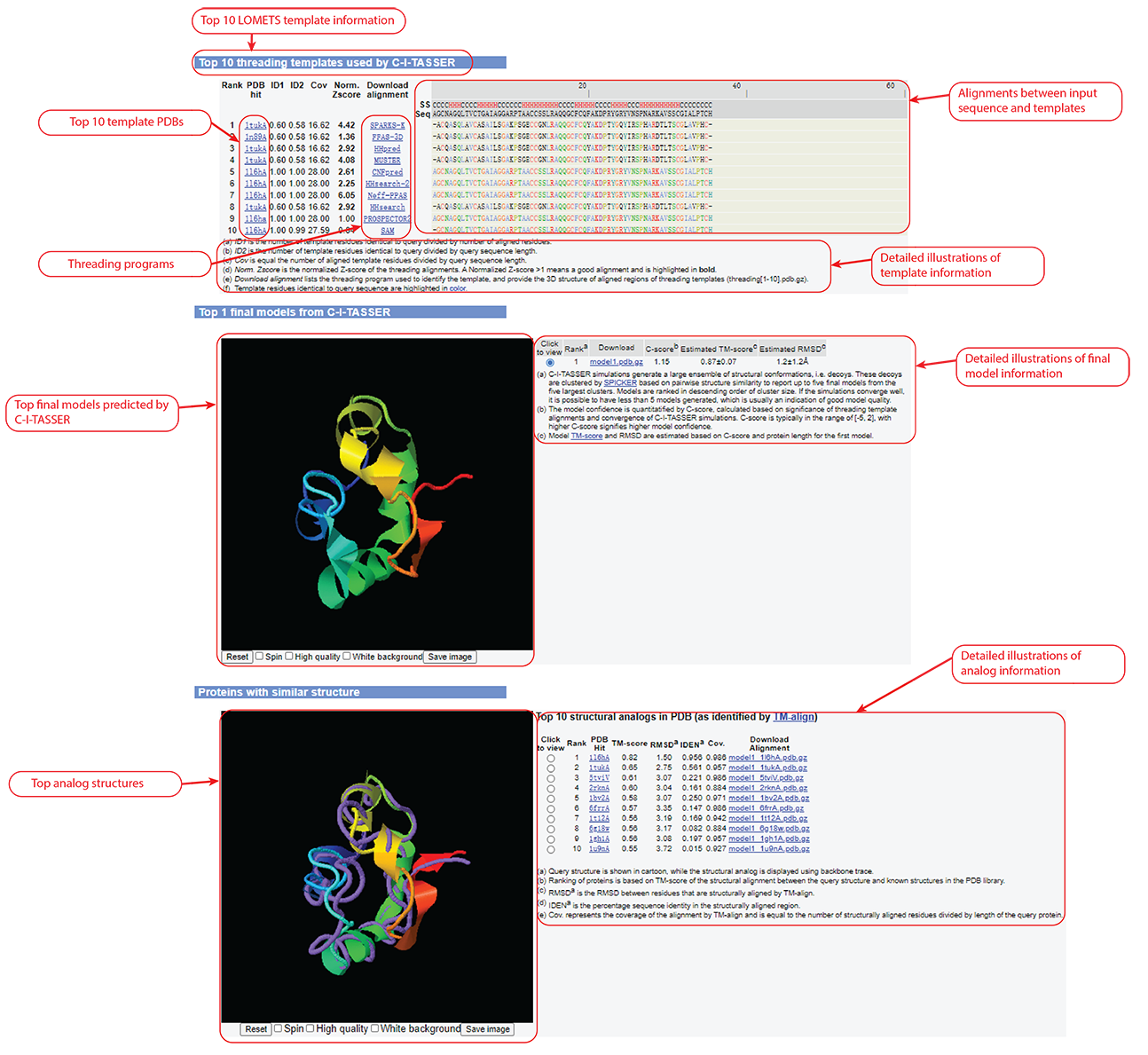 Figure 5. Templates, final models, and analog information in C-I-TASSER output.
Figure 5. Templates, final models, and analog information in C-I-TASSER output.
 Figure 6. Gene Ontology (GO) Term prediction information in the C-I-TASSER output. This information is output only after you check the "Predict protein function based on structure model (running time may be doubled)." option of the input.
Figure 6. Gene Ontology (GO) Term prediction information in the C-I-TASSER output. This information is output only after you check the "Predict protein function based on structure model (running time may be doubled)." option of the input.
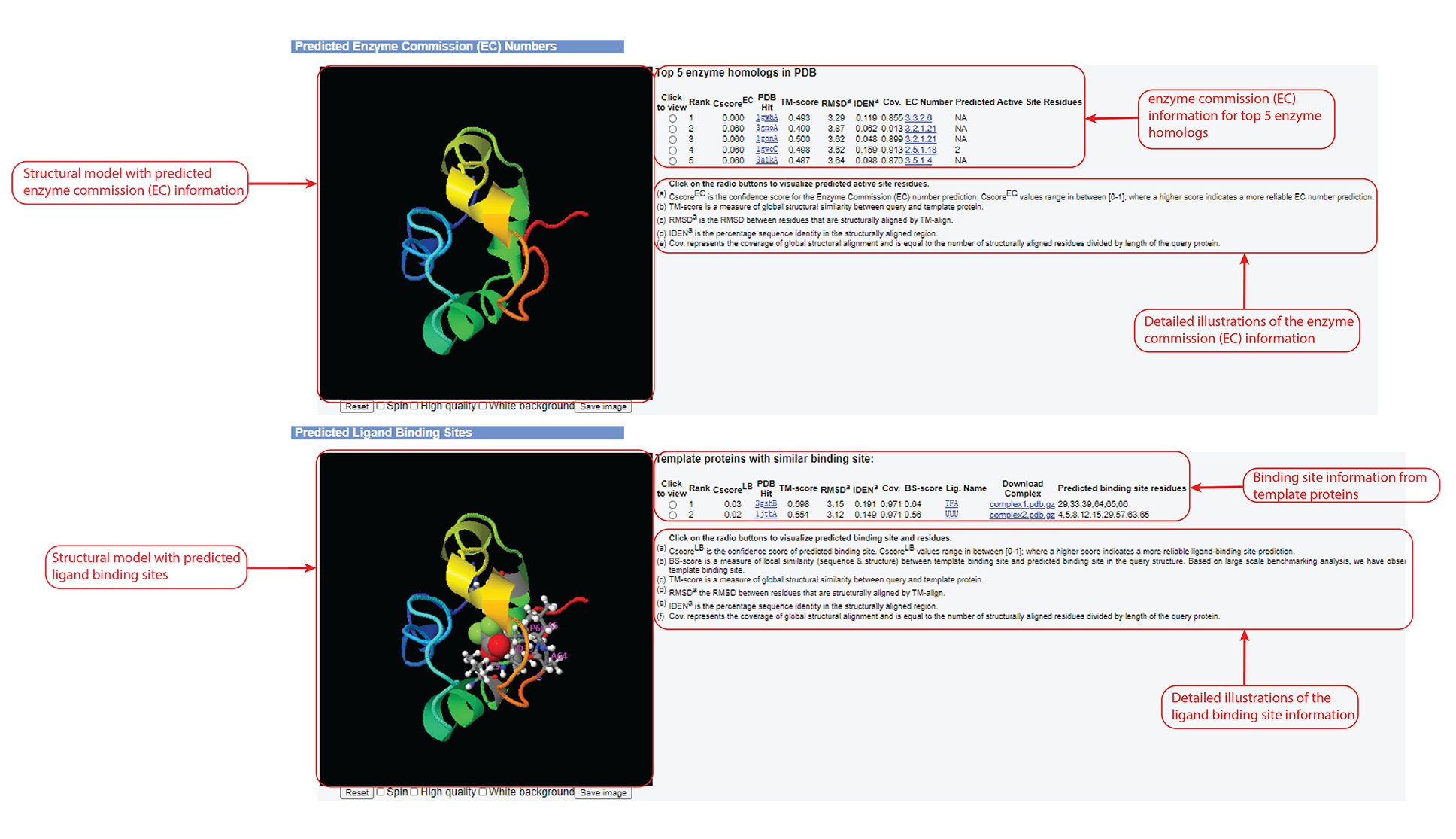 Figure 7. Enzyme Commission (EC) and ligand binding site prediction information in the C-I-TASSER output. This information outputs only after you check the "Predict protein function based on structure model (running time may be doubled)." option of the input.
Figure 7. Enzyme Commission (EC) and ligand binding site prediction information in the C-I-TASSER output. This information outputs only after you check the "Predict protein function based on structure model (running time may be doubled)." option of the input.
C-I-TASSER modeling starts from the structure templates identified by LOMETS2 from the PDB library. LOMETS2 is a meta-server threading approach containing multiple threading programs, where each program can generate tens of thousands of templates. C-I-TASSER only uses the templates of the highest significance in the threading alignments, which are measured by the Z-score (the difference between the raw and average scores in the unit of standard deviation). The top 10 templates are the 10 templates selected from the LOMETS2 threading programs. Usually, one (or two) template with the highest Z-score is selected from each threading program, where the threading programs are sorted by the average performance in the large-scale benchmark test experiments.
For each target, C-I-TASSER simulations generate tens of thousands of conformations (called decoys). To select the final models, C-I-TASSER uses the SPICKER program to cluster all the decoys based on pair-wise structure similarity, and report up to five models which correspond to the five largest structure clusters. In Monte Carlo theory, the largest clusters correspond to the states of the largest partition function (or lowest free energy) and therefore have the highest confidence. The confidence of each model is quantitatively measured by C-score (see below). Since the top 5 models are ranked by the cluster size, it is possible that the lower-rank models have a higher C-score. Although the first model has a higher C-score and a better quality in most cases, it is not unusual that the lower-rank models have a better quality than the higher-rank models. If the C-I-TASSER simulations converge, it is possible to have less than 5 clusters generated. This is usually an indication that the models are high quality because of the converged simulations.
After the structure-assembly simulation, C-I-TASSER uses the TM-align program to match the first C-I-TASSER model to all structures in the PDB library. This section reports the top 10 proteins from the PDB which have the closest structural similarity (i.e. the highest TM-score) to the predicted C-I-TASSER model. Due to their structural similarity, these proteins often have similar function to the target. However, users are encouraged to use the function prediction in C-I-TASSER output to obtain the biological function of the target protein, since C-I-TASSER predicts the function using COACH and COFACTOR, which have been extensively trained to derive function from many sequence and structure features, and as a result, these programs have a much higher accuracy than function annotations derived only from the global structure comparison.
Since the experimental structures are unknown for the user input sequence, we have designed a confidence score (C-score) to quantitatively estimate the quality of the C-I-TASSER models. The C-score is a linear combination of three components: significance of the LOMETS2 threading alignments, satisfaction rate of the predicted contact-maps, and the decoy convergence degree of the C-I-TASSER simulations. Based on benchmark testing, the C-score had a Pearson correlation coefficient (PCC) of 0.80 with TM-score. As a result of this high correlation, we were able to select a C-score cutoff of -2.5, corresponding to an estimated TM-score=0.5, and attain a Matthews correlation coefficient (MCC) on the benchmark dataset of 0.623 and a false discovery rate (FDR) of only 6.88%. Therefore, the C-I-TASSER models with C-score > -2.5 are considered to be successfully folded.
C-score is a confidence score for estimating the quality of predicted models by C-I-TASSER. It is calculated based on the significance of threading template alignments, the convergence parameters of the structure assembly simulations, and the contact satisfaction rates. A C-score of higher value signifies a model of high confidence.
TM-score is a metric for measuring the structural similarity between two structures (see Zhang and Skolnick, Scoring function for automated assessment of protein structure template quality, Proteins, 2004 57: 702-710). The purpose of proposing TM-score is to solve the problem of RMSD which is sensitive to local errors. Because RMSD is an average distance of all residue pairs in two structures, a local error (e.g. a misorientation of the tail) will result in a big RMSD value although the global topology is correct. In TM-score, however, the small distance is weighted stronger than the big distance, which makes the score insensitive to local modeling errors. A TM-score > 0.5 indicates a model of correct topology and a TM-score < 0.17 means a random similarity. These cutoffs are not dependent on the protein length.
TM-score (or RMSD) is a known standard for measuring structural similarity between two structures and is typically used to measure the accuracy of structure modeling when the native structure is known. C-score is a metric that was developed for C-I-TASSER to estimate the confidence of modeling. In the case where the native structure is not known, it becomes necessary to use the C-score predict the quality of the modeling prediction, i.e. the distance between the predicted model and the native structures.
In a benchmark test set of 797 proteins, we found that C-score is highly correlated with TM-score. The correlation coefficient of the C-score of the first model with the TM-score to the native structure is 0.80. These data lay the base for the reliable prediction of the TM-score using C-score. In the output section, C-I-TASSER only reports the quality prediction (TM-score and RMSD) for the first model, because it was found that the correlation between C-score and TM-score is weak for lower rank models. However, the C-score is listed for all models for reference.
We have found that the cluster size is more robust than C-score for ranking the predicted models. The final C-I-TASSER models are therefore ranked based on cluster size rather than C-score in the output. Nevertheless, the C-score has a strong correlation with the quality of the final models, which has been used to quantitatively estimate the RMSD and TM-score of the final models relative to the native structure. Unfortunately, such strong correlation only occurs for the first predicted model from the largest cluster. Thus, the C-scores of the lower-rank models (i.e., models 2-5) are listed only for reference and a comparison among them is not advised. In other words, even though the lower-rank models may have a higher C-score than the first model in some cases, the first model is on average the most reliable and should be considered first, unless the user has special reasons to choose other models (e.g., from biological sense or experimental data).
zhanglab![]() zhanggroup.org
| +65-6601-1241 | Computing 1, 13 Computing Drive, Singapore 117417
zhanggroup.org
| +65-6601-1241 | Computing 1, 13 Computing Drive, Singapore 117417